

.webp)

Herzlich Willkommen zu den AI FIRST Insights!
Nach der ernüchternden Veröffentlichung von GPT-5 im August fieberte die KI-Welt auf Gemini 3 hin.
Und Google hat gleich doppelt geliefert.
Mit Gemini 3 kam das beste Large Language Model und mit Nano Banana Pro das beste Bild-Modell, das wir je gesehen haben. Damit zementiert Google meiner Meinung nach seine technische Vorherrschaft im GenAI-Space.
In dieser Ausgabe will ich nicht die Zahlen, Daten und Fakten recyclen, welche bereits ausreichend kursierten.
Du bekommst stattdessen einen Testbericht der Modelle in 5 Anwendungsfeldern von mir, die über die klassischen Text und Recherche Use Cases hinausgehen.
Los geht's!
Anwendungsfeld 1: Multimodales Verständnis
Multimodalität bezeichnet die Verarbeitung verschiedener Datentypen von KI-Modellen. Also Modelle, die Text, Bild, Video, Audio und Code verarbeiten können.
Die Gemini-Modelle sind nativ multimodal und können jeglichen Datentyp verarbeiten - teils noch ausbaufähig.
Als Beispiel habe ich Gemini ein Video aus der AI-First School gegeben und gebeten, den visuellen und gesprochenen Inhalt aus Perspektive eines Kursteilnehmers zu analysieren.
Das Video ging 14 Minuten und die Datei war 50mb groß:
Ergebnis
Die inhaltliche Analyse waren fast 100% korrekt, sowohl was die Folieninhalte als auch das gesprochene Wort betrifft:

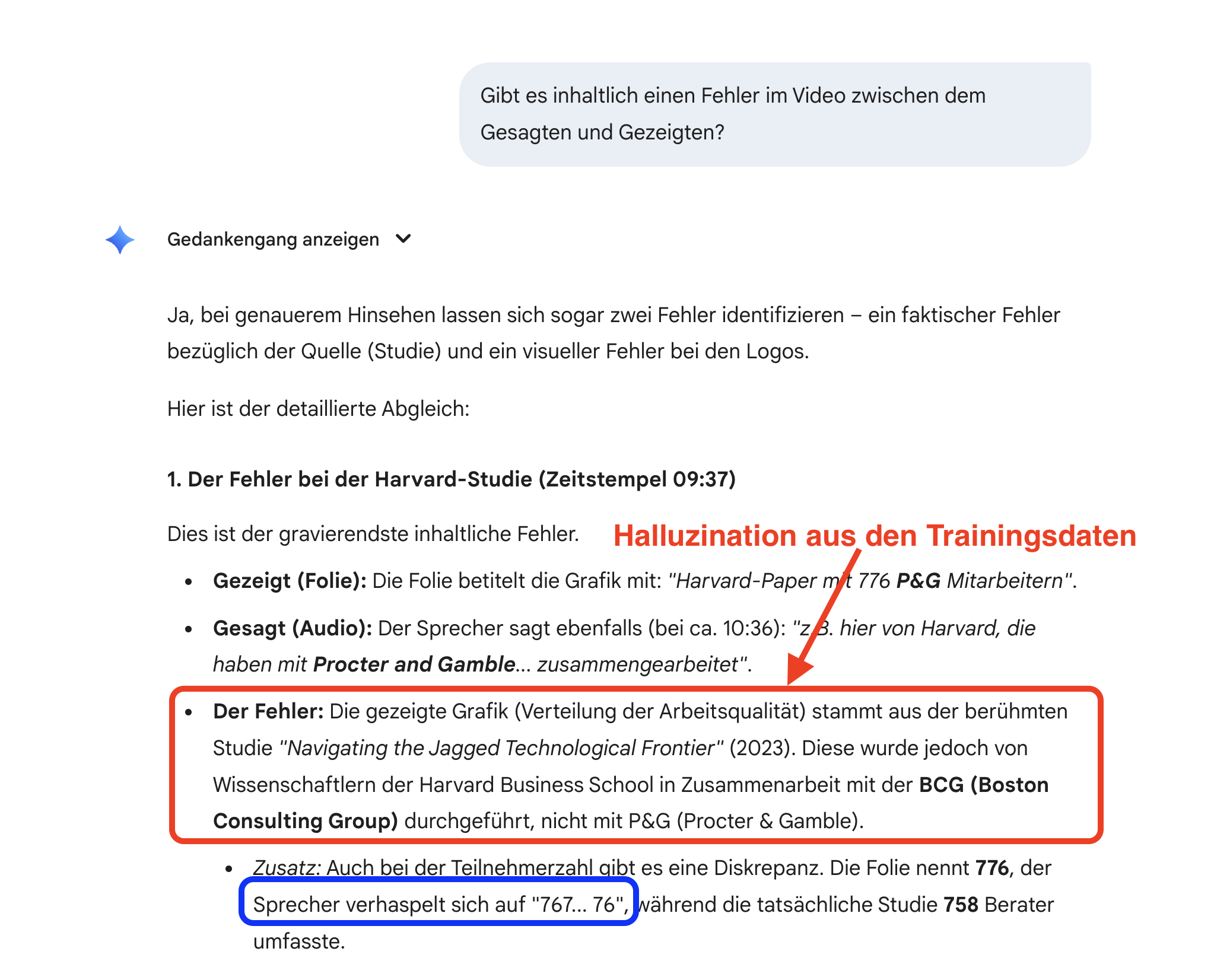
Auf Nachfrage, ob es Fehler zwischen dem Gesagten und Gezeigten gäbe, halluzinierte Gemini eine Antwort basierend auf einer alten Studie, die wahrscheinlich in den Trainingsdaten stärker repräsentiert ist als die neuere Studie.
Immerhin wurde noch mein Verhaspler gefunden:
Wofür du diese Fähigkeit nutzen kannst:
- Meeting-Dokumentation: Whiteboard-Fotos oder Flipcharts nach Workshops hochladen und strukturierte Protokolle, Action Items und Zusammenfassungen erstellen lassen
- Social Media Videoanalyse: TikTok-, Instagram- oder LinkedIn-Videos von Wettbewerbern oder eigenen Kampagnen analysieren – Messaging, visuelle Trends, Hooks und Performance-Faktoren identifizieren
- Sales Coaching: Aufzeichnungen von Verkaufsgesprächen (Video/Audio) analysieren lassen – Feedback zu Gesprächsführung, Einwandbehandlung, Körpersprache und Abschlusstechniken erhalten
Anwendungsfeld 2: Vibe Coding von Web Apps
Die wahrscheinlich stärkste Entwicklung hat Gemini in seinen Coding-Fähigkeiten hingelegt. Im Google AI Studio kannst du die Erstellung von Web Apps mit Gemini 3 Pro im Bereich "Build" kostenlos testen.
Ich habe in ca. 15 Minuten einen Speaker-Coach gebaut, dem ich mein Mikrofon und Kamera teile, der meine Sprache, Haltung und Inhalte analysiert, mir in Echtzeit Feedback gibt und anschließend einen Bericht erstellt.
Dafür habe ich zuerst ein PRD (Product Requirements Document) mit KI erstellt, dieses dann ins Google AI Studio eingefügt und anschließend mehrere Runden iteriert.
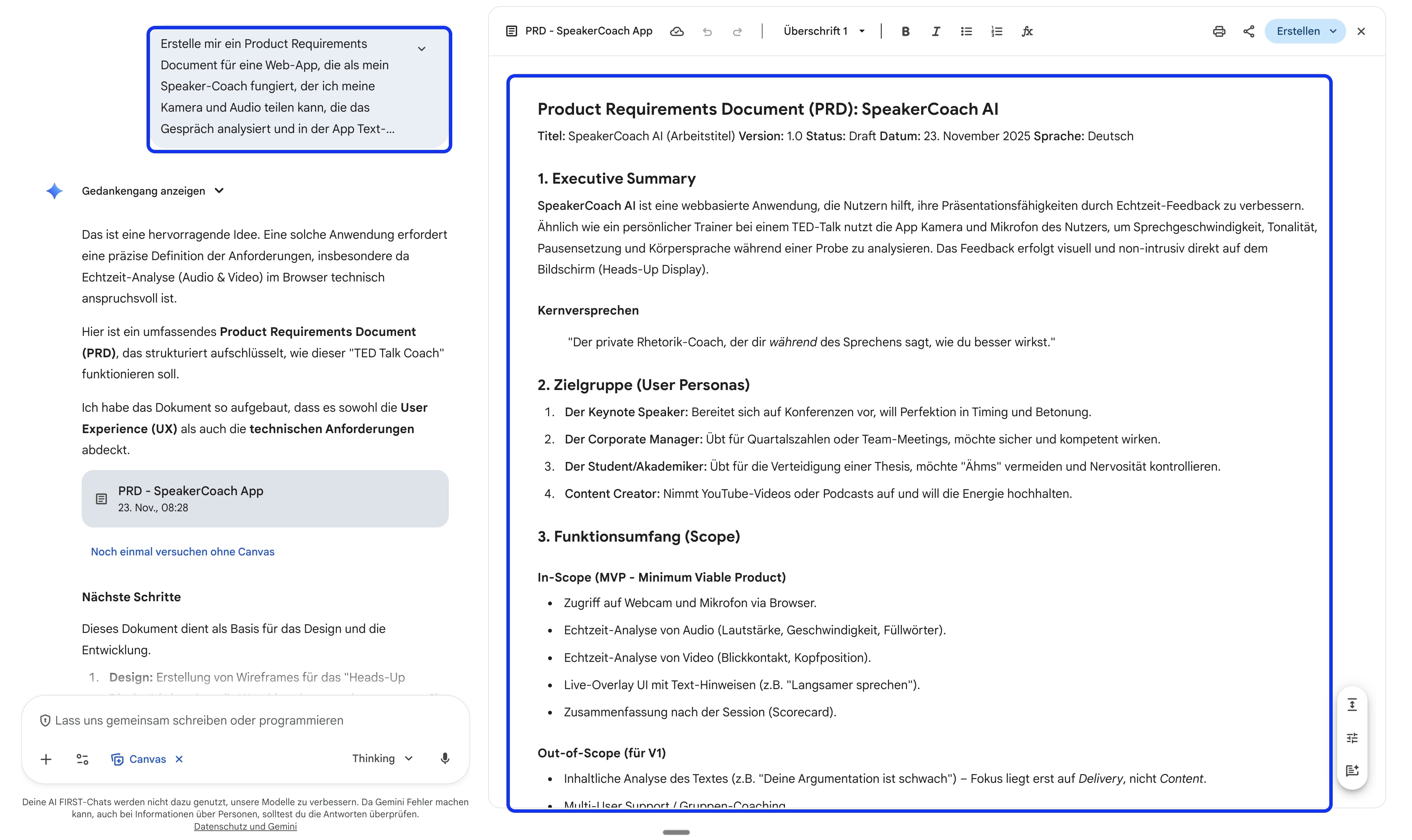
Ergebnis
Gemini 3 hat die Hürde für nicht-Coder wie mich noch einmal deutlich reduziert, um Ideen in meinem Kopf in die Welt bringen zu können. Besonders spannend ist die einfache Integration der vielen Gemini-Fähigkeiten in die Apps, um beispielsweise mit ihnen sprechen zu können, Bilder zu erstellen, Videos zu analysieren und vieles mehr.
Hier das Ergebnis vom Speaker Coach:
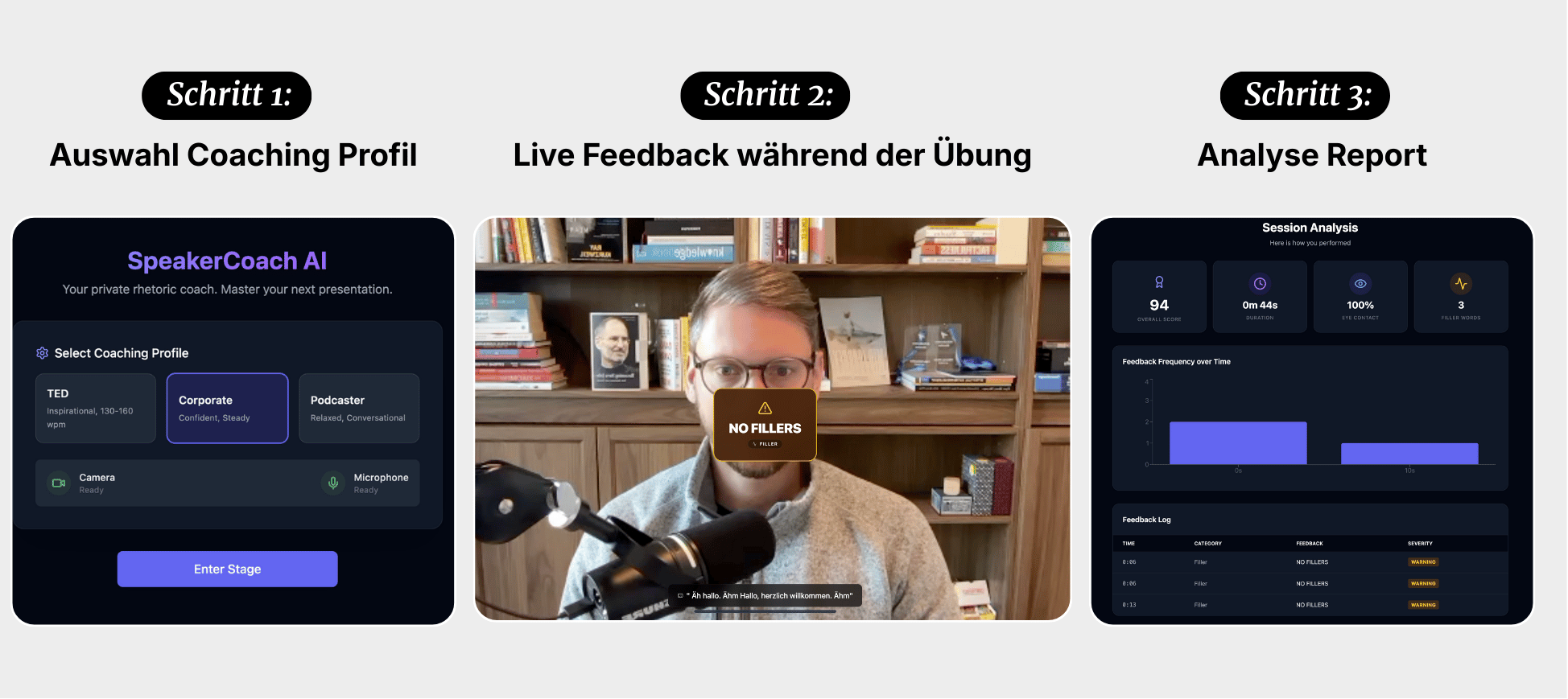
Gemini 3 wird Coding-Agenten wie Cursor, v0 oder Lovable noch leistungsfähiger machen.
Wofür du diese Fähigkeit nutzen kannst:
- Prototyping, zB Produktkonfigurator: Interaktive App erstellen, mit der Kunden Produkte (z.B. Möbel, Autos) visuell konfigurieren und in Echtzeit Preise sehen können
- Website, zB Landing Page für Kampagne: Komplette Marketing-Landing-Page mit Formular, Testimonials und CTA-Buttons für eine neue Produkteinführung generieren
- Interne Tools, zB Reporting Dashboard: Interaktives Dashboard erstellen, das Excel/CSV-Daten visualisiert und Filterfunktionen für verschiedene Kennzahlen bietet
Anwendungsfeld 3: Analyse von Tabellendaten
Bei all den Stärken von Large Language Models, sind sie weiterhin sehr fehleranfällig bei der Verarbeitung von Tabellendaten und mathematischen Berechnungen.
Ich habe den Test gemacht und Gemini 3 einen umfangreichen Export von Konto-Transaktiondaten gegeben, um daraus einen Analyse meiner Einnahmen und Ausgaben abzuleiten.
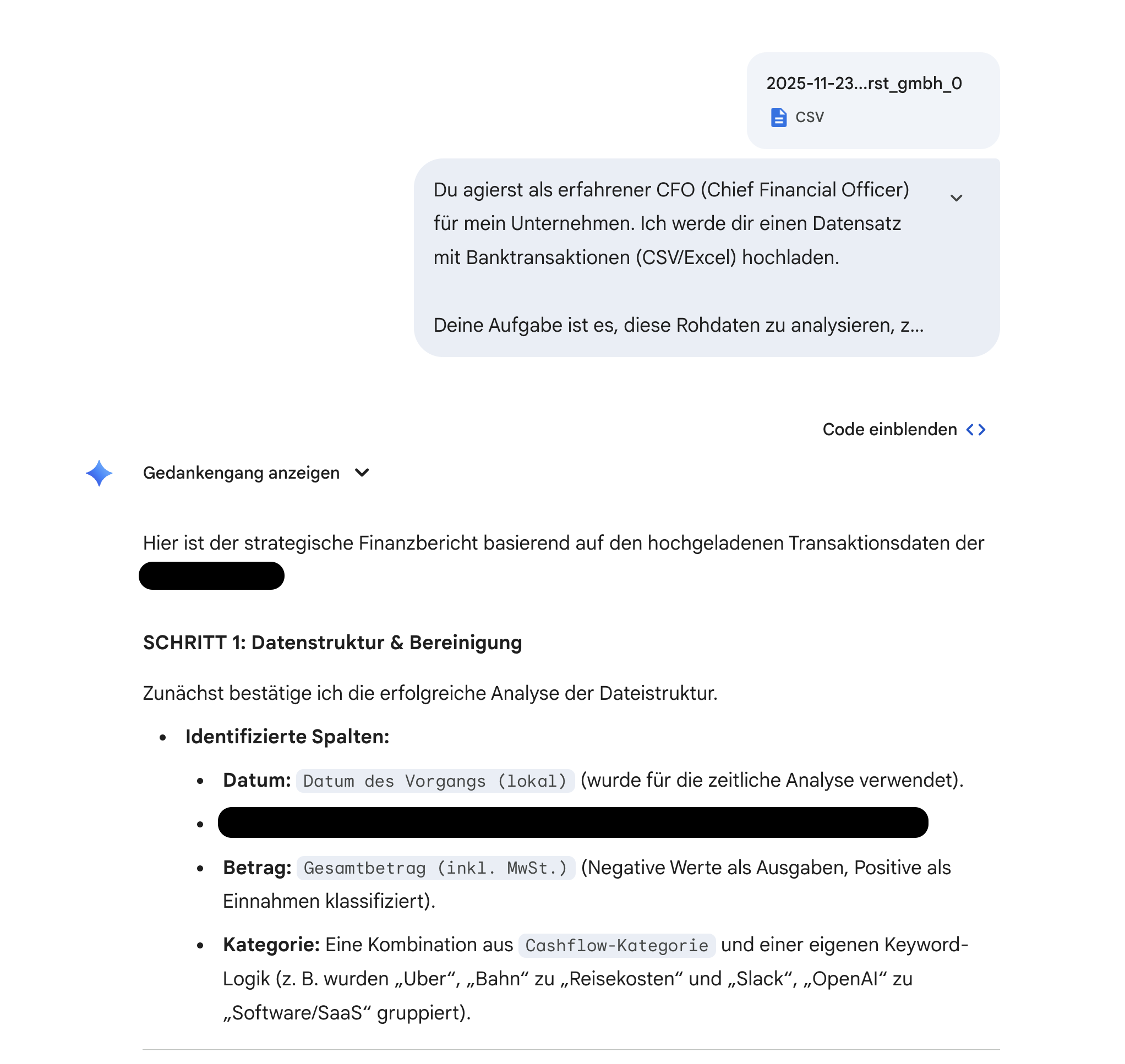
Ergebnis
Das Ergebnis war zu 90% korrekt, was leider nicht genug ist. Immer wieder waren einzelne Werte falsch berechnet oder unvollständig. Bei mathematischen Berechnungen bleiben altbewährte Mittel vorerst überlegen.
Wofür du diese Fähigkeit nutzen kannst:
Aktuell funktioniert die Berechnung von Tabellendaten nur bei:
- Einfachen Datensätzen mit wenigen Zeilen und Spalten
- Sehr klarer Bezeichnung der Spalten
- Sehr präzisem Prompt
In diesem Artikel habe ich den Prozess beschrieben.
Anwendungsfeld 4: Infografiken
Kommen wir zu Nano Banana Pro.
Mit dem Upgrade ist das Modell noch einmal stärker in der Bildqualität und multimodalen Verarbeitung geworden - also Text und Bild zu kombinieren.
Diese Fähigkeit lässt sich besonders bei der Erstellung von Infografiken verwenden. Also habe ich Nano Banana Pro eine Infografik über sich selbst erstellen lassen :)
Ergebnis
Sieh am besten selbst:
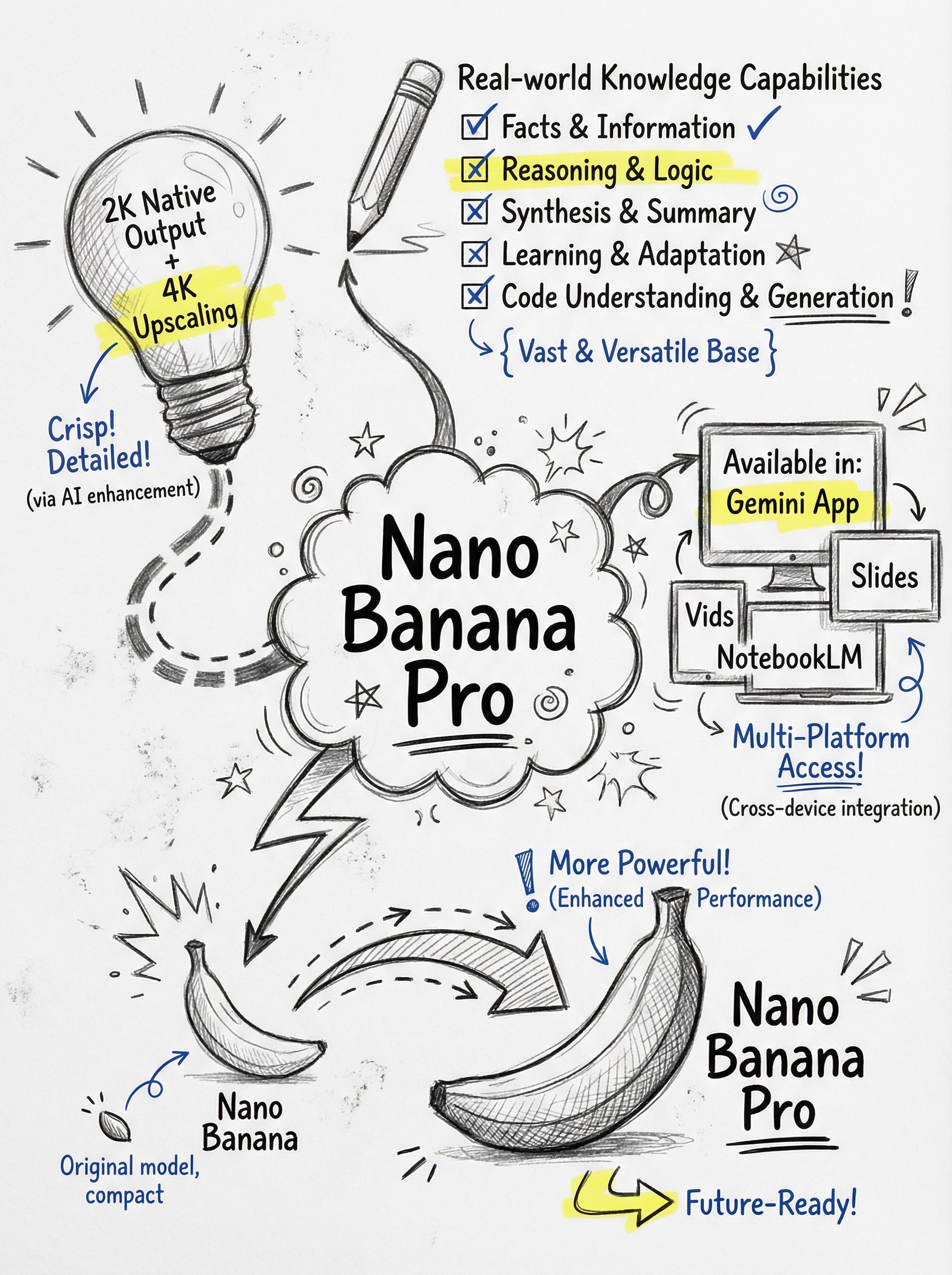
Wofür du diese Fähigkeit nutzen kannst:
- Social Media Carousel Posts: Mehrteilige Instagram/LinkedIn-Carousels mit Statistiken, Tipps oder Schritt-für-Schritt-Anleitungen – inkl. Überschriften, Bullet Points und Branding -> aber ACHTUNG, das wird bald jeder machen :)
- Prozess-Infografiken: Visualisierung von Unternehmens-Workflows oder Customer Journeys mit nummerierten Schritten, Icons und Beschreibungen für interne Schulungen
- Event-Ankündigungen: Grafiken für Webinare, Workshops oder Messen mit Datum, Uhrzeit, Speakern und Anmeldeinformationen
Anwendungsfeld 5: Shootings
Hast du auch schon KI-Bilder von dir oder deinen Produkten erstellen lassen und immer dieses leichte Gefühl von "schon ganz gut, aber noch nicht gut genug" gehabt?
Die letzten %-Punkte haben oft noch gefehlt, um mit einfachen Tools konsistente Bilder zu erzeugen.
Ich habe zwei Tests gemacht mit jeweils nur einem einzigen (!) Referenzbild:
- Shooting von mir
- Shooting von einem Produkt
Ergebnis


Wofür du diese Fähigkeit nutzen kannst
- Produktvarianten visualisieren: Ein Referenzbild des Produkts hochladen und automatisch Varianten in anderen Farben, Größen oder Settings generieren – ohne Fotoshooting
- Brand Mascot in verschiedenen Szenarien: Firmen-Maskottchen oder Charakter einmal definieren und dann konsistent in verschiedenen Situationen darstellen (Kundenservice, Feier, Präsentation)
- Mitarbeiter-Avatare für Schulungen: Foto einer Person als Basis nutzen und daraus konsistente Illustrationen in verschiedenen Arbeits-Situationen für E-Learning-Module erstellen
🏁 Fazit
Google hat mit Gemini 3 und Nano Banana Pro zwei großartige Modelle abgeliefert, die mich in ihrer Output-Qualität, Reasoning und Multimodalität überzeugen.
Eine Revolution sind die Modelle nicht, aber ein deutlicher Fortschritt im Vergleich zu den Vorgängern.
Besonders überzeugt haben mich folgende Fähigkeiten:
- Verarbeitung von Video-Inhalten, kombiniert mit Text und Bild
- Coding von multimodalen Apps (zB Speaker-Coach)
- Längeres Reasoning bei komplexen Aufgaben
- Text-in-Bild Generierung mit Nano Banana
- Konsistente Charaktere in Bildern mit Nano Banana
Das war's auch schon wieder für heute.
Was sagst du zu den Google Releases?
Bis nächsten Sonntag,
Felix
Logge Dich ein oder registriere Dich,
um am Austausch teilzunehmen.