
Die Lernschleife im KI-Betriebssystem
Wie sich dein KI-Betriebssystem selbst verbessert
Herzlich Willkommen zu den AI FIRST Insights! Dies ist der letzte Teil der Serie über die Bausteine unseres KI-Betriebssystems und wie wir diese Bausteine designed haben.
Die bisherigen Artikel findest Du hier:
- Agenten: Die Ausführungseinheit auf dem Betriebssystem
- Skills (Prozesse): Alles, was unsere Organisation kann
- Kontext (Daten): Alles, was unsere Organisation weiß
- Governance (Regeln): Alle Regeln, die für KI gelten
Heute kommt der letzte Baustein: die Lernschleife.
Ich zeige Dir, wie wir dafür gesorgt haben, dass unser KI-Betriebssystem mit jeder Ausführung besser wird.
Los geht's!
Warum KI-Systeme aufhören zu lernen
Bevor wir das Betriebssystem gebaut haben, hatten wir 25 spezialisierte KI-Agenten. Jeder konnte bestimmte Aufgaben erledigen. Und jeder hatte dasselbe Problem: Er wurde nur besser, wenn wir aktiv etwas dafür getan haben.
Wenn ein Agent einen Fehler gemacht hat, mussten wir daran denken, den Fehler in seine Anweisung einzubauen. Wenn sich ein Prozess verändert hat, mussten wir daran denken, die Anpassung bei allen betroffenen Agenten vorzunehmen. Wenn eine neue Aufgabe dazukam, mussten wir daran denken, einen neuen Agenten aufzusetzen.
Wie ein Mitarbeiter, dem wir immer wieder Feedback und Training geben mussten.
Die Weiterentwicklung war komplett menschenabhängig.
Das ist der Normalzustand in fast jedem KI-Setup: Du setzt Agenten und Automatisierungen auf, investierst am Anfang viel Zeit in die richtige Konfiguration, das Prompt-Design und die Output-Struktur. Irgendwann liefert der Agent gute Ergebnisse. Aber wenn sich dein Prozess oder deine Anforderungen weiterentwickeln, bricht diese Qualität.
Fehler wiederholen sich, weil niemand sie erfasst. Feedback versickert in Chat-Verläufen und niemand setzt es um. Und wenn jemand das Team verlässt, geht das implizite Wissen einfach mit.
Bei dutzenden bis hunderten Agenten in vielen Unternehmen wird genau das zu einer massiven Herausforderung. Auch wir hatten diese Probleme und wollten sie in unserem Setup systemisch endlich lösen.
Warum haben wir “Lernen” ins System eingebaut?
Im ersten Artikel dieser Serie habe ich fünf Werkzeuge des systemischen Denkens vorgestellt. Eines davon waren Rückkopplungsschleifen: Das Ergebnis einer Aktion fließt zurück und beeinflusst die nächste Aktion.
Genau dieses Prinzip haben wir als festen Bestandteil in unser Betriebssystem eingebaut. Eine zentrale Designentscheidung von Anfang an: Alles, was die KI tut, muss strukturiert zurück ins System fließen.
Das betrifft vier Bereiche:
- Fehler, die bei der Ausführung auftreten
- Neuer Kontext, der durch die Ausführung entsteht
- Ergebnisse, die von KI produziert werden - für volle Nachvollziehbarkeit
- Verbesserungsvorschläge, wenn die KI erkennt, dass ein Prozess optimiert werden kann
Fließt all das wieder automatisch ins System zurück,
- kann KI Fehler selbst korrigieren
- behält KI den vollständigen Kontext
- behalten Menschen den Überblick
- erweitert sich das System fortlaufend
Ich will damit erreichen, dass die Weiterentwicklung nicht ausschließlich von uns abhängt, sondern das System sich Stück für Stück selbst verbessern kann.
Wie lernt das System konkret dazu?
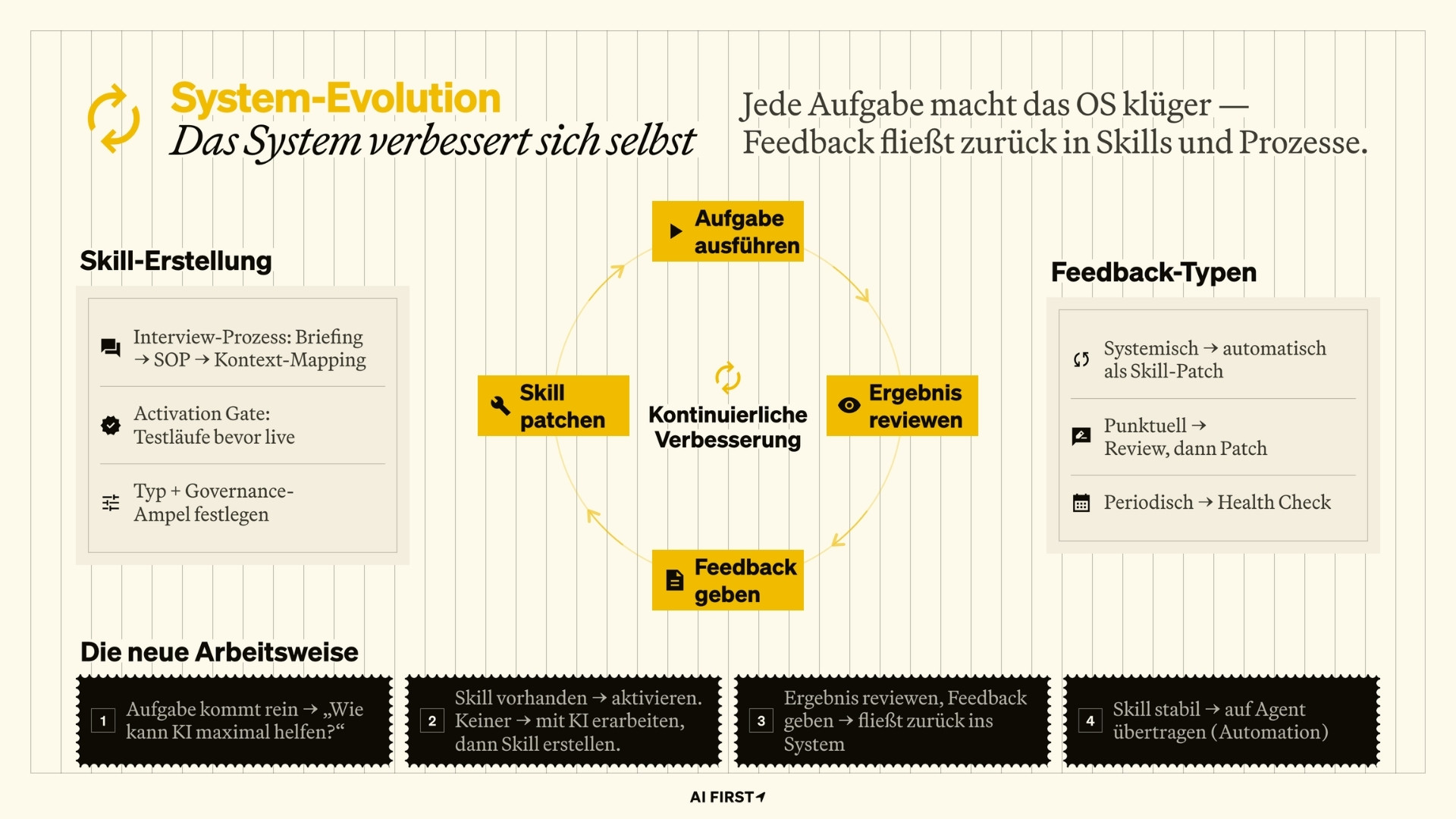
Wir haben drei Feedback-Pfade aufgebaut, die unterschiedliche Situationen abdecken. Alle drei haben dasselbe Ziel: Wissen nicht in Köpfen, Drittsystemen oder Chat-Verläufen hängenbleiben lassen, sondern ins System zurückführen.
Pfad 1: Stille Skill-Optimierung
Die ersten Feedback-Schleifen laufen schon vor der ersten echten Ausführung. Bevor ein neuer Skill live geht, durchläuft er ein Activation Gate: Die KI generiert Testfälle basierend auf der Arbeitsanweisung, der Skill-Owner führt die Testläufe anhand der generierten Fälle durch und prüft die Ergebnisse gegen die Definition of Done. Nach jedem Testlauf wird Feedback gegeben, das in den Skill integriert wird. Erst nach mehreren erfolgreichen Durchläufen geht der Skill live. Die Qualitätssicherung ist permanenter Teil des Systems.
Nach Skill-Freigabe erfolgt die Optimierung fortlaufend.
Ich führe einen Skill aus, das Ergebnis passt nicht ganz – und ich gebe Feedback direkt im Gespräch mit der KI. „Das Format muss zu XYZ geändert werden." „Bitte immer mit einer Zusammenfassung starten." „Keine Hashtags unter den Post."
Die KI entscheidet: Ist das ein dauerhaftes Learning, das den Skill betrifft? Wenn ja, passieren drei Dinge gleichzeitig:
- Sie korrigiert den aktuellen Output
- Sie passt die Arbeitsanweisung des Skills an
- Sie protokolliert das Learning im Skill
Beim nächsten Mal muss niemand mehr daran denken. Der Skill ist für alle Nutzer besser geworden.
Um diese “stille Skill-Optimierung” durchzuführen, hat der OS-Agent folgenden Abschnitt in seiner Systemanweisung:
### Schritt 7: Performance loggen + Skill-Learning (optional)
- User kann manuell Feedback geben → geht in [Feedback-DB]
**Stilles Skill-Learning (User-Feedback only, Pflicht-Write):**
Wenn der User Feedback gibt, das eine **Skill-Eigenschaft** betrifft (Ton, Format, Struktur, Regeln, No-Gos, DoD, Schritte), dann entscheide:
- **Wenn eindeutig systemisch:** Kein Nachfragen. Setze das Learning um.
- **Wenn unklar (Output-only vs. systemisch):** Stelle genau 1 Rückfrage: *„Soll ich das als dauerhaftes Learning in den Skill übernehmen? (ja/nein)"*
**Pflicht-Aktionen (wenn "ja" oder eindeutig systemisch):**
1. **Sofort im aktuellen Output umsetzen**.
2. **Skill-Update:** Ergänze genau **eine** konkrete Regel an der passendsten Stelle im Skill (z.B. unter No-Gos/Regeln/DoD oder direkt im relevanten Schritt). Kein Rewrite, kein großer Refactor.
3. **Learning Log (append-only):** Ergänze im Skill unter **📝 Learnings** genau 1 Zeile mit Datum + 1 Satz (Regel-Formulierung).
4. **Einzeilige Bestätigung:** *„✏️ Learning notiert und Skill gepatcht."*
**Proaktive Feedback-DB-Erkennung:**
Wenn du während der Execution oder nach User-Feedback feststellst, dass ein Problem **über einen direkten Skill-Patch hinausgeht** (systemisch, fehlender Skill, Kontext-Lücke, Governance-Problem, Architektur-Thema):
→ Schlage dem User proaktiv vor: *„Dieses Feedback geht über einen Skill-Patch hinaus. Soll ich einen Eintrag in der Feedback-Datenbank erstellen?"*
→ Nach Bestätigung: Eintrag in [Feedback-DB) erstellen (Skill-Relation, Feedback-Typ, Beschreibung).Pfad 2: Die Feedback-Datenbank
Nicht jedes Problem lässt sich durch einen einfachen Skill-Patch lösen. Manchmal betrifft ein Fehler mehrere Skills gleichzeitig. Manchmal fehlt ein ganzer Skill für eine Aufgabe. Manchmal stimmt die Governance-Einstufung nicht, oder eine Kontext-Quelle ist veraltet.
Für alles, was über einen einzelnen Skill hinausgeht, haben wir eine zentrale Feedback-Datenbank aufgebaut – ein Ticketing-System für systemische Verbesserungen.
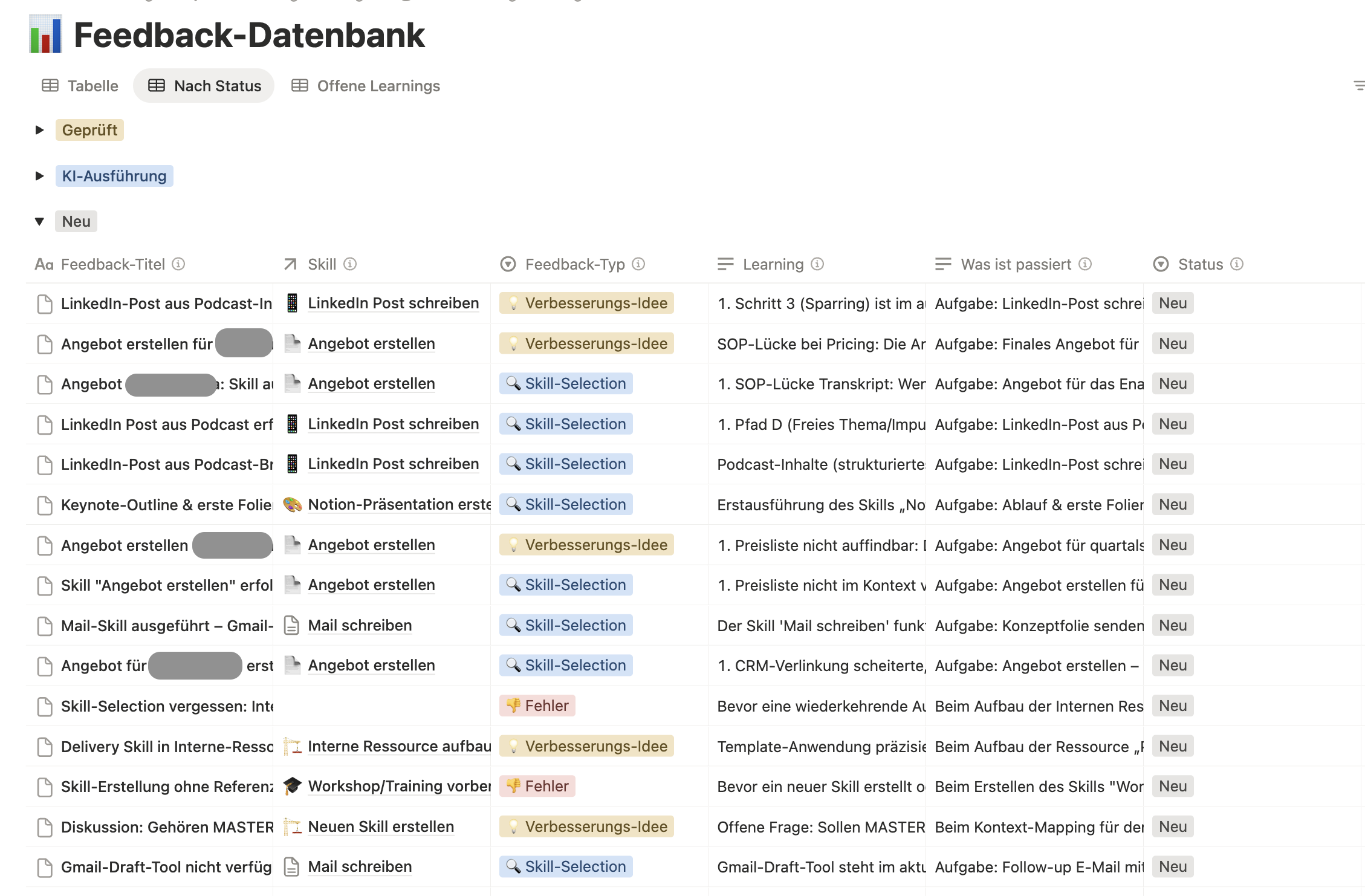
Ausschnitt aus der Feedback-DB
So funktioniert es: Die KI dokumentiert bei jeder Ausführung automatisch, ob etwas nicht wie erwartet gelaufen ist, ob Informationen gefehlt haben oder ob sie einen Verbesserungsvorschlag hat. In unserer Agenten-Pipeline übernimmt das der Feedback Logger – der letzte Agent in der Kette, der nach jeder Ausführung prüft, ob es etwas zu dokumentieren gibt.
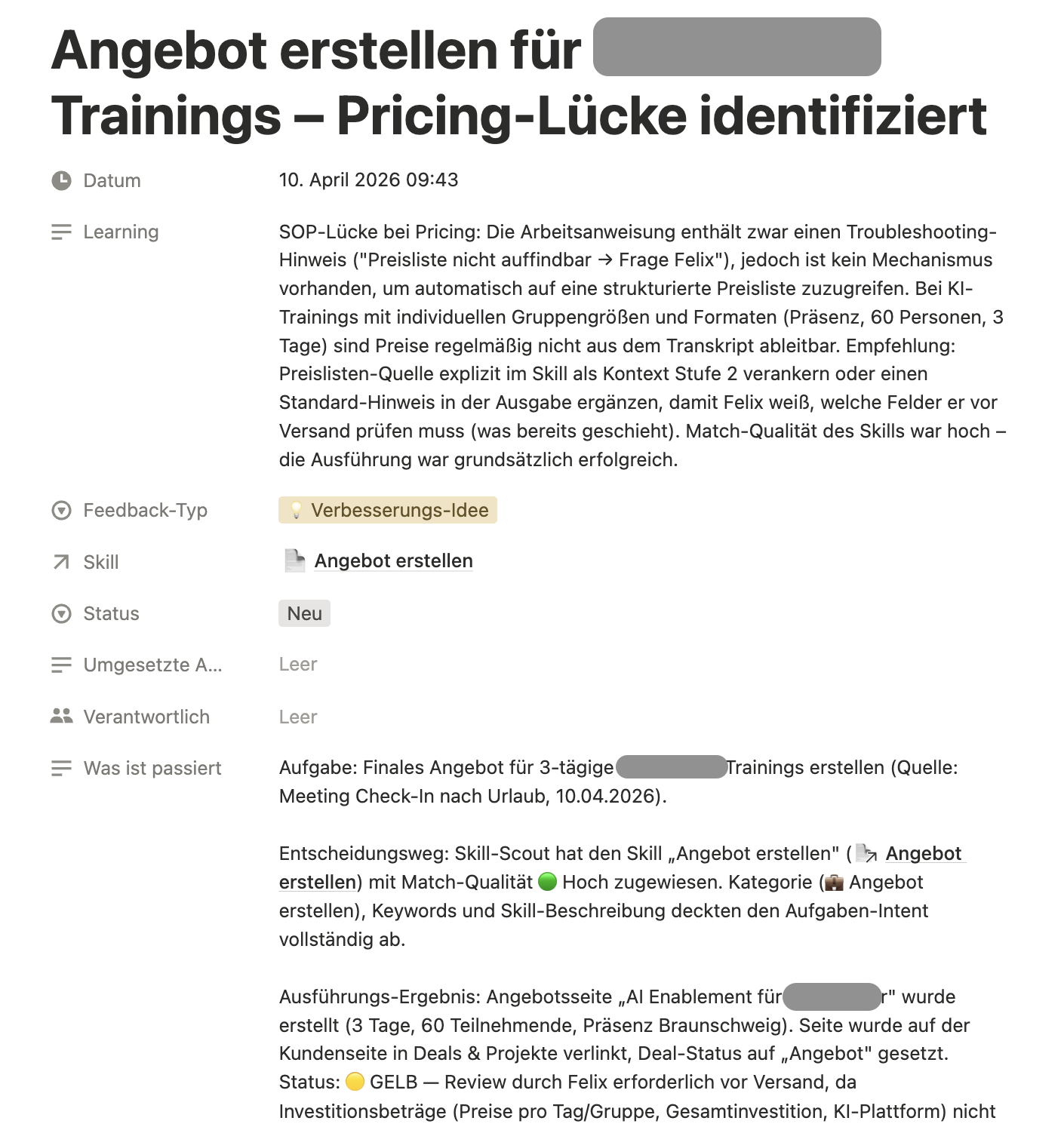
Beispiel-Dokumentation aus der Feedback-DB
Wichtig dabei: Die KI arbeitet kein strukturelles Feedback eigenständig ein. Ein Mensch muss jeden Eintrag prüfen und freigeben. Erst nach der Freigabe setzt die KI die Änderung um – sei es eine Anpassung an einem Skill, eine Erweiterung des Kontexts oder eine neue Governance-Regel.
Wir hatten anfangs versucht, das vollständig zu automatisieren. Bei Hunderten Aktionen pro Woche floss jedoch so viel Feedback zurück und wurde ins System integriert, dass wir irgendwann nicht mehr nachvollziehen konnten, was sich wann verändert hat. Wir mussten mehrfach Änderungen rückgängig machen. Seitdem gibt es dieses Gate – und die Qualität im System ist deutlich stabiler.
Pfad 3: Kontext-Erweiterung
Jede Ausführung erzeugt neuen Kontext. Du dokumentierst ein Meeting. Du erstellst ein Angebot. Du setzt ein Kundenprojekt auf. All das ist Wissen, das die KI beim nächsten Mal braucht.
In unserem System fließt dieser Kontext automatisch in die entsprechenden Datenbanken zurück. Die KI legt das Meeting-Transkript strukturiert ab, referenziert das Angebot auf der Kundenseite und verlinkt die Projekt-Dokumentation in der Kontext-Karte.
Das System wird mit jeder Aufgabe nicht nur besser in der Ausführung, sondern auch klüger im Kontext. Die KI weiß beim nächsten Angebot für denselben Kunden, was beim letzten Mal besprochen wurde. Sie kennt die bisherigen Projekte, die Präferenzen, die offenen Punkte. Niemand hat das manuell gepflegt. Das System ist so gebaut, dass Kontext automatisch zurückfließt.
Was passiert, wenn ein System sich selbst verbessert?
Früher hatten wir ein System, das Aufgaben erledigt. Jetzt haben wir ein System, das Aufgaben erledigt und dabei besser wird.
4 Vorteile machen für mich den Unterschied:
- Fehler wiederholen sich nicht. Ein einmal geloggtes Learning wird beim nächsten Mal berücksichtigt, ohne dass jemand daran denken muss.
- Skills stagnieren nicht. Sie entwickeln sich mit jeder Ausführung weiter. Unsere ältesten Skills sind heute deutlich besser als bei ihrer Erstversion.
- Wissen bleibt im System. Wenn jemand das Team verlässt, gehen die Learnings nicht mit. Sie leben in den Skills, im Kontext und in der Feedback-Datenbank.
- Neue Fähigkeiten entstehen von selbst. Wenn eine Aufgabe reinkommt, für die kein Skill existiert, kann das System sich selbst einen neuen Skill bauen – weil das Erstellen neuer Skills selbst ein dokumentierter Skill ist.
Je mehr Aufgaben die KI ausführt, desto mehr Learnings sammelt sie, desto besser werden die Arbeitsanweisungen, desto besser werden die Ergebnisse.
Das ist die verstärkende Rückkopplungsschleife, die das gesamte System antreibt.
🏁 Fazit
Mit der Lernschleife schließen wir die KI-Betriebssystem-Serie.
In den letzten Wochen habe ich alle Bausteine einmal erklärt:
- Die 5 Bausteine – das Gesamtbild, wie Skills, Kontext, Governance, Executor und Feedback-Layer zusammenspielen
- Das Skill-Playbook – was ein Skill ist, wie man ihn baut und wo man ihn schon heute anlegen kann
- Der Agentic Layer – wie drei Agenten-Typen auf dem System arbeiten
- Die Governance – welche Regeln gelten und wie die Ampel-Logik Kontrolle schafft
- Die Lernschleife – wie das System mit jeder Nutzung besser wird
Der größte Hebel kam nicht von einem einzelnen Baustein, sondern davon, dass alle Bausteine zusammenspielen. Ein Skill allein ist eine gute Arbeitsanweisung. Aber ein Skill, der seinen Kontext kennt, sich an Governance hält, von einem generischen Executor flexibel ausgeführt werden kann und über die Lernschleife besser wird – das erzeugt den eigentlichen Hebel.
Falls du in den letzten Wochen mitgelesen hast: Danke. Ich hoffe, die Serie hat dir einen Eindruck gegeben, wie ein KI-Betriebssystem aussehen kann. Wir schrauben schon fleißig an Version 2 unseres Systems und ich werde auch in Zukunft unsere Erfahrungen mit Dir teilen.
Bis nächsten Sonntag,
Felix
P.S. Ich plane für die kommende Woche eine Q&A-Ausgabe zum KI-Betriebssystem und werde auf alle eure Fragen eingehen. Antworte dafür einfach mit deinen Fragen auf diese Mail - danke!
Registriere dich kostenlos,
um den vollständigen Artikel zu lesen.
vollständige Insights
Hub-Werkzeugen
und diskutiere mit
an einem Ort






