



Herzlich Willkommen zu den AI FIRST Insights!
KI und Excel – das klingt nach dem Dream-Team.
Erwartung: Tabelle hochladen, Frage stellen, perfekte Analyse bekommen.
Realität: Der Chatbot rechnet falsch, versteht Spalten nicht oder erfindet Zahlen.
Das Problem ist kein Fehler der KI, sondern ein grundlegendes Missverständnis.
Ein Large Language Model ist ein Sprachkünstler, kein Datenanalyst.
Es "liest" deine Tabelle nicht, sondern wandelt sie in einen langen Text um.
In dieser Ausgabe zeige ich dir, warum das so ist und wie du mit einem einfachen 3-Schritte-Prozess und den richtigen Werkzeugen bessere Ergebnisse bekommst.
Los geht's!
Bringe dein Unternehmen erfolgreich in die KI-Ära
Vor 3 Monaten habe ich das AI Collective mit der Mission gegründet, Führungskräfte im Mittelstand fit für die KI-Ära zu machen.
Ab September öffenen wir das AI Collective für weitere Mitglieder, die die KI-Transformation in ihrem Unternehmen vorantreiben.

Wenn du bereit bist, die KI-Verantwortung in deinem Unternehmen zu übernehmen und deine Karriere auf die nächste Stufe zu heben, ist das deine Einladung.
👉 Mehr über das AI Collective erfahren
Das Kernproblem: Eine KI "sieht" keine Tabelle
Um zu verstehen, warum ChatGPT & Co. oft scheitern, müssen wir einen Blick unter die Haube werfen. Das Kernproblem ist fundamental: Ein Large Language Model (LLM) "sieht" keine Excel-Tabelle wie ein Mensch.
Stell Dir vor, Du nimmst Deine saubere Tabelle und kopierst den gesamten Inhalt – Zelle für Zelle, von links nach rechts und von oben nach unten – in eine einzige, lange Textdatei. Ungefähr so nimmt eine KI Deine Daten wahr. Dieser Prozess nennt sich Linearisierung.
Produkt A, 100, 150, 50, Produkt B, 120, 140, 20, Produkt C, 90, 90, 0
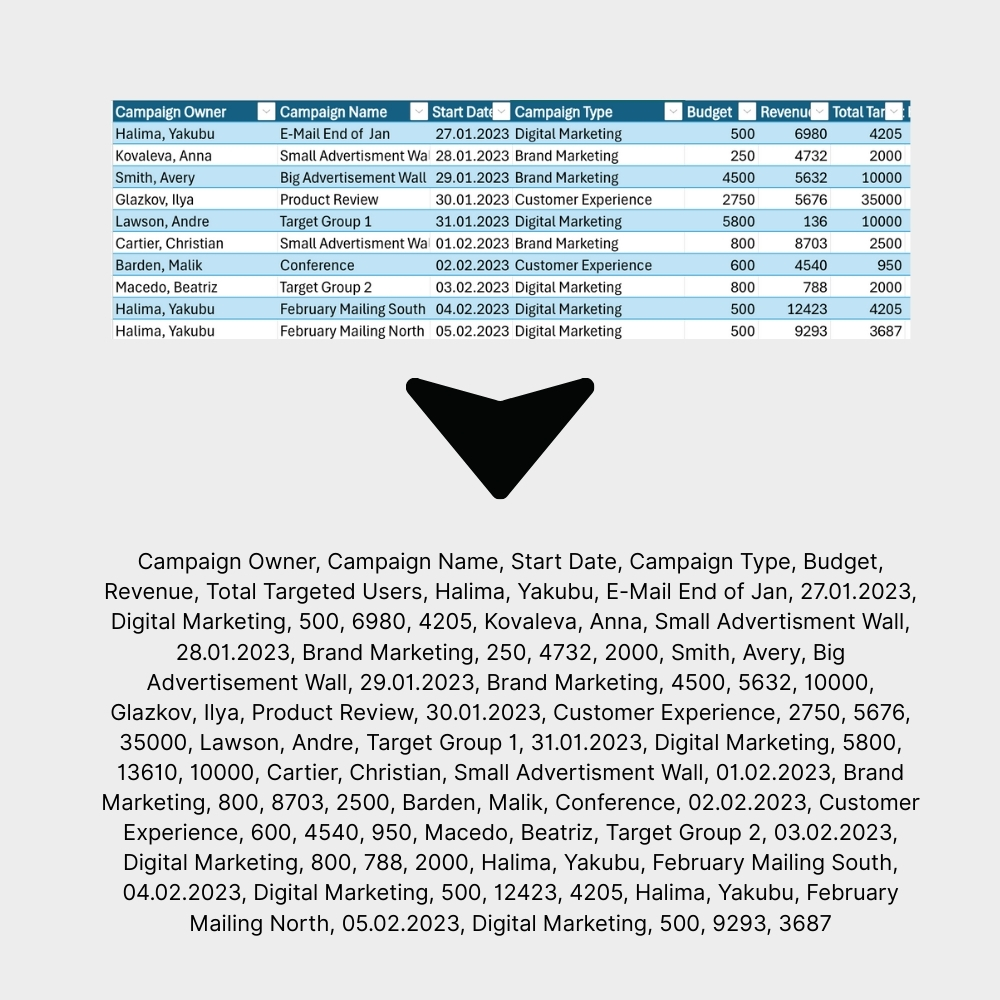
Was geht dabei verloren? Alles, was für uns Menschen den Kontext gibt:
- Die visuelle Struktur: Die KI weiß nicht, dass "150" in Spalte C steht und zum "Produkt A" aus Spalte A gehört. Es ist nur ein Wort in einer langen Kette.
- Die Bedeutung der Spalten: Ohne explizite Anweisung ist "Umsatz Q2" nur eine Zeichenfolge, keine Kennzahl mit einer bestimmten Bedeutung.
- Logische Zusammenhänge: Die Beziehung zwischen verschiedenen Zeilen oder die Logik einer Berechnung existiert in diesem reinen Text-Format nicht mehr.
Man nennt dieses Problem den "Dimensionality Mismatch": Ein zweidimensionales Werkzeug (deine Tabelle) trifft auf ein eindimensionales System, das nur Textsequenzen versteht (das Sprachmodell).
Dazu kommt eine zweite, entscheidende Schwäche: LLMs sind Sprachkünstler, keine Mathematiker. Sie sind darauf trainiert, die wahrscheinlichsten nächsten Token vorherzusagen, nicht, präzise zu rechnen. Eine einfache Summe mag oft klappen, aber komplexe Berechnungen sind eher geraten als exakt kalkuliert.
Die direkten Folgen sind die Fehler, die du kennst:
- Kontextverlust: Die KI weiß nicht mehr, welcher Wert zu welcher Spalte gehört.
- Falsche Berechnungen: Die KI "schätzt" nur, statt exakt zu rechnen.
- Halluzinierte Daten: Die KI erfindet Werte, die nicht existieren.
Die Lösung: 3 Schritte für bessere Ergebnisse
Wie lösen wir das Problem? Immerhin bleibt Excel-Auswertung ein Aufgabenfeld, in dem wir täglich viel Zeit verbringen.
Der Schlüssel liegt darin, dem Modell den Kontext zu geben, den es verliert, und es die richtigen Werkzeuge nutzen zu lassen.
Schritt 1: Bereite deine Daten vor (Das Fundament)
Der Grundsatz "Müll rein, Müll raus" gilt hier zu 100%. Bevor du überhaupt an die KI denkst, musst du deine Daten "LLM-freundlich" machen.
- Struktur schaffen: Entferne konsequent alles, was die tabellarische Logik stört: verbundene Zellen, mehrzeilige Überschriften, leere Zeilen.
- Klarheit herstellen: Gib jeder Spalte einen eindeutigen, selbsterklärenden Namen (z.B. Umsatz_in_EUR statt Ums.). Das ist die wichtigste Information, die du der KI für den Kontext geben kannst.
- Als CSV exportieren: Kopiere Daten nicht einfach. Der Export als CSV-Datei ist die sauberste Methode, da die Struktur am zuverlässigsten in ein Textformat übersetzt wird, das die KI lesen kann. Markdown funktioniert noch besser.
Schritt 2: Gib präzise Anweisungen (Das Briefing)
"Analysiere diese Datei" oder "Gib mir alle Insights aus diesen Kampagnen-Daten" wird nie zum Ziel führen. Wir müssen spezifischer in unseren Anweisungen sein:
- Der Kontext: Was ist das für eine Datei? "Ich habe eine CSV-Datei mit Kundendaten hochgeladen."
- Das Ziel: Was soll am Ende herauskommen? "Ich möchte die Top-3-Länder nach Gesamtumsatz ermitteln."
- Die Details: Welche Spalten sind dafür relevant? "Nutze dafür die Spalten 'Land' und 'Gesamtumsatz'."
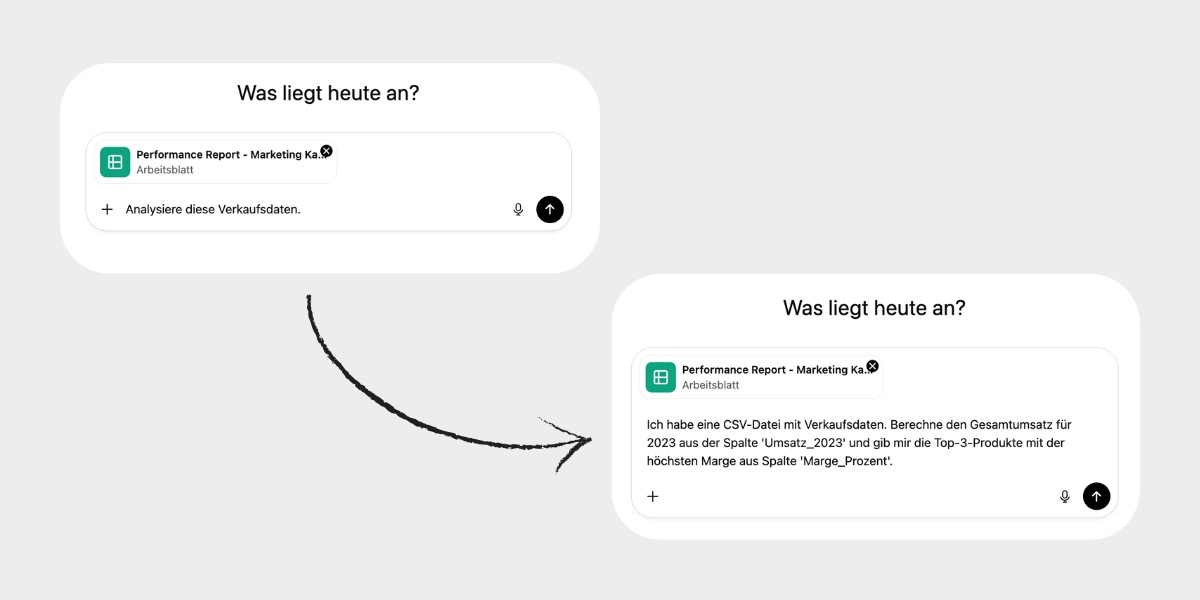
Bonus Tipp: Prompte zum Start "Lies die hochgeladene CSV-Datei ein und zeige mir die ersten 3 Zeilen sowie eine Liste aller Spaltennamen an." Wenn hier schon etwas falsch ist (z.B. Spalten falsch getrennt), weißt du sofort, dass du bei der Datenvorbereitung nachbessern musst.
Schritt 3: Nutze den Code Interpreter / Data Analyst
LLMs können nicht rechnen. ChatGPT, Copilot, Gemini und Co. geben den LLMs aus diesem Grund ein Werkzeug an die Hand, das einen Python-Code schreibt, um die Rechenoperation auszuführen.
Wie funktioniert das?
- Du gibst eine Anweisung: "Erstelle mir ein Balkendiagramm der Umsätze pro Quartal."
- Die KI schreibt Code: Das LLM übersetzt deine Anweisung in präzisen Python-Code.
- Der Code wird ausgeführt: Dieser Code wird in einer sicheren "Sandbox" ausgeführt.
- Das Ergebnis wird angezeigt: Das Resultat des Codes (Zahl, Tabelle, Diagramm) wird dir im Chat angezeigt.
Indem du die KI anweist, den Code Interpreter zu nutzen, verlagerst du die Arbeit von der unzuverlässigen "Sprach-Schätzung" zur "Code-Ausführung".
Wichtig: Auch der Code Interpreter kann Fehler machen, indem er einen falschen Code schreibt, der zu falschen Ergebnissen führt. Außerdem gibt es Zeitlimits, die die Ausführung komplexer Berechnungen oft blockieren.
Ausblick: Was erwartet uns im Excel-KI-Markt?
Die Entwicklung im Markt für tabellenbasierte KI-Verarbeitung geht jetzt erst richtig los.
Auch hier sind KI-Agenten ein Weg, um die Komplexität des mehrschrittigen Aufgabenprozesses mit KI-Fähigkeiten zu bewältigen.
Es gibt eine Reihe an Unternehmen, die antreten, um dieses Problem zu lösen:
- Google: Mit der Integration von Gemini in Google Colab baut Google einen Data Science KI-Agenten, der mit einem eigenen Jupyter Notebook arbeitet (nutzen sonst nur Data Scientists oder Programmierer).
- Microsoft: Mit dem Analyst Agent und der Copilot Excel-Funktion hat Microsoft in den letzten Monaten gleich zwei Funktionen herausgebracht, die die Verarbeitung und Erstellung von Tabellen vereinfacht.
- Shortcut: Integriert sich nahtlos in Excel, übernimmt typische Aufgaben der Tabellenverarbeitung per Prompt in einer Chat-Leiste und automatisiert komplexe Analysen und Datenrecherchen.
- Endex: Eine von OpenAI finanzierte Lösung, die speziell für Finanzexperten entwickelt wurde und direkt in Microsoft Excel eingebettet ist, eigenständig strukturierte Analysen sowie Berichte erstellt.
- Paradigm: Paradigm ersetzt klassische Excel-Formeln, indem es pro Tabelle hunderte autonome KI-Agenten einsetzt, die routinemäßige Berechnungen und individuelle Arbeitslogik automatisieren.
Wie mit allen KI-Agenten, sind auch diese Tools bisher nicht unfehlbar, benötigen genaue Anweisungen und menschliche Ergebniskontrolle.
Aber der Weg ist klar: Wir werden in Zukunft deutlich weniger Zeit mit der Erstellung und Auswertung von Tabellen verbringen.
🏁 Fazit
Die Frustration bei der Analyse von Tabellen mit KI ist verständlich. Aber sie basiert nicht auf einem Versagen der KI, sondern auf einem Missverständnis ihrer Natur. Ein LLM ist ein Sprachkünstler, kein Mathematiker.
Sobald wir das verstanden haben und aufhören, es zum Rechnen zu zwingen, können wir seine wahre Stärke nutzen: als Übersetzer unserer Absichten in Code.
Key Takeaways:
- KI "sieht" keine Tabellen: Sie linearisiert Daten zu Text, wodurch die Struktur verloren geht (Dimensionality Mismatch).
- Nutze den Code Interpreter: Zwinge die KI nicht, selbst zu rechnen. Lass sie Code schreiben, der die Berechnung für dich erledigt. Das ist der entscheidende Hebel.
- Vorbereitung ist alles: Saubere Daten und präzise Prompts sind 90% des Erfolgs. Müll rein, Müll raus.
- Das Rennen hat erst begonnen: Viele Start Ups sowie Google und Microsoft arbeiten an KI-Agenten, die die Auswertung und Erstellung von Tabellen weiter vereinfachen werden.
Viel Spaß und Erfolg bei der Anwendung der Tipps und beim Testen der Tools!
Bis nächsten Sonntag,
Felix




Logge Dich ein oder registriere Dich,
um am Austausch teilzunehmen.